Close
Talk to JBS today(877) JADE-BIZ

Problem Statement: Fragmented Data & Slowed Innovation in Drug Discovery
A leading biopharmaceutical research team faced significant bottlenecks during the early phases of drug discovery, particularly in target identification and hypothesis formulation. The root challenges stemmed from:

Manual Research Compilation
Scientists spent 10–15% of their time collecting data from disparate sources such as PDFs, internal documents, and online repositories.
Scientists spent 10–15% of their time collecting data from disparate sources such as PDFs, internal documents, and online repositories.

Data Silos Across Formats
Disparate structured and unstructured data—ranging from clinical trial reports and journals to Excel sheets—created fragmented knowledge.
Disparate structured and unstructured data—ranging from clinical trial reports and journals to Excel sheets—created fragmented knowledge.

Delayed Research Cycles
Manual workflows extended research timelines, reducing time spent on innovative therapeutic exploration.
Manual workflows extended research timelines, reducing time spent on innovative therapeutic exploration.
Solution: AI-Powered Data Lake & NLP-Driven Research Platform
To address these challenges, the team implemented a centralized biomedical data lake and enabled automated natural language processing (NLP) pipelines to streamline research and discovery:

Multi-Omics Data Integration
Unified genomics, proteomics, and transcriptomics datasets for comprehensive analysis during early-stage R&D.
Unified genomics, proteomics, and transcriptomics datasets for comprehensive analysis during early-stage R&D.
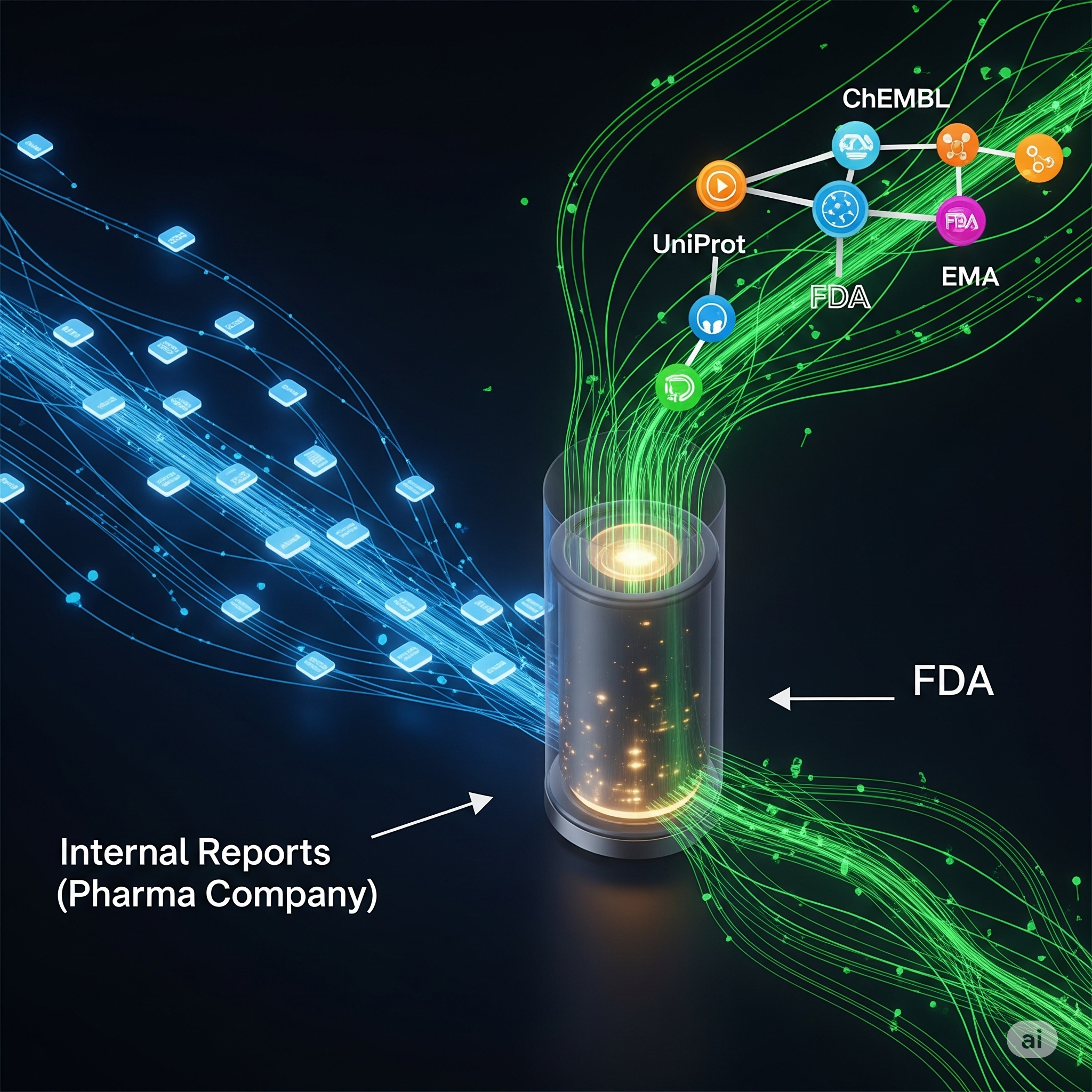
Centralization of Research Repositories
Aggregated internal findings and reports from Jazz Pharma alongside public databases (e.g., ChEMBL, UniProt, FDA, EMA).
Aggregated internal findings and reports from Jazz Pharma alongside public databases (e.g., ChEMBL, UniProt, FDA, EMA).

NLP-Powered Query & Discovery Engine
Enabled scientists to run advanced natural language queries on the entire data lake, uncovering patterns across articles, notes, and publications in seconds.
Enabled scientists to run advanced natural language queries on the entire data lake, uncovering patterns across articles, notes, and publications in seconds.
Unified View of Structured & Unstructured Data
Created a single source of truth for drug targets, pathways, and therapeutic candidates.
Created a single source of truth for drug targets, pathways, and therapeutic candidates.
Business Benefits: Accelerated Innovation, Reduced Overhead

10–15% Time Saved
on repetitive data collection through automation.
on repetitive data collection through automation.

Faster Turnaround Times
in research phases via streamlined data access and NLP-driven insights.
in research phases via streamlined data access and NLP-driven insights.

Improved Decision-Making
Comprehensive, real-time data visibility accelerated hypothesis testing and drug target evaluation.
Comprehensive, real-time data visibility accelerated hypothesis testing and drug target evaluation.

Higher ROI on Research
Scientists focused more on high-impact experimentation instead of data prep.
Scientists focused more on high-impact experimentation instead of data prep.
Technology Stack

Azure Data Lake Storage

Azure VNet
Azure Key Vault

Databricks
Microsoft Azure

Role-based access controls, secure credential vaults